497
Did my bank send me this email or is that a scam?

Once in a while I get a few emails telling me that this or that bank account of mine is compromised in some way and to fix it I have to follow a link and log in to my account. Once there, I'll have to proceed with one or two more security questions possibly.
This happens with all large banks. I have not seen it much with smaller banks. Probably because the scammers did not even hear about those smaller banks and a local bank only cater to local people and it's difficult to get a list of those people specifically. Instead, a list of Amercans in general is going to be much easier to get and you are way more likely to get some Return On Investment (because it takes some time to create those fake pages and hackers have an interest in gaining access to some user accounts. In sales, we call that "the law of numbers." Hit more people with your sales pitch and you will get sales going through.)
"Valid" URL
I wanted to write a blog post about it because today I again received one where the email was pretty well done in that the link pretty much looked like a valid Citibank link. Well, the visible part of the link (what we call the anchor text.) The real link, what most people don't even know how to find out (or even know to pay attention to,) was of course totally incorrect, although it started as expected. Another plus to the hacker since that makes it more likely that someone will follow the link thinking it is genuine.
So, the email had the following URL:
https://online.citi.com/US/login.do?JFP_TOKEN=TGZUBM4U
As we can see, it says "online.citi.com" which is the correct URL for Citibank users to log in.
The "US" part is added if you are in the US and therefore you can tell that the hacker is attempting to get the credential of some American bank accounts. Again the "US" is correct as far as the standard Citibank login is concerned.
Further, it says "login.do" which his the path to the login page. Again, this is correct for Citibank regular users.
Next, the "JFP_TOKEN" part is also visible when you go to the login page. However, that they go it somewhat wrong. But really you need to know how websites function to notice that there is a problem here. How's that? You might ask... Well... To create a safer form, you give it a random number (TGZUBM4U in the hacker's example.) This bunch of of letters and numbers represent a unique token that is created along the form. When you answer the form, that specific token is returned to the server along your answer (i.e. so your browser sends back your username, password, and that random number.) If the number doesn't match or is out of date, then the login fails no matter what. That is, whether the form had a valid username and password or not, the answer is that the login failed because the token is not valid. The "out of date" part is important because if you start entering your info and then leave the computer without first login in or deleting what you entered, someone else could come behind you and click the Login button. As a result that other user would gain access to your bank account. In case of a login form, that amount is pretty small (like a few minutes). This is why if you go to the login screen, feel like you should go to the toilet, which takes you a few minutes, come back and try to log in, it generally fails. Most often the bank doesn't tell you that the problem was a time out to not alert the hackers of why the login did not work because that way the hacker is more likely to think that your credential were invalid.
There is an easy way to see the content of the login and password input fields using F12 and using the console to print the content of those fields. Say the password field has the identifier set to "password" as follow:
<input type="password" id="password"/>
In you regular window the password will look like a bunch of dots:
Getting the password from that field works like this, assuming that the bank makes use of jQuery (which makes the script really easy, but it is not required to get the very same results):
console.log(jQuery("#password").val());
This code says:
1. console.log() — write the result of the function call within the parenthesis in your console (F12 & click on the Console tab)
2. jQuery("#password") — find the widget with attribute id="password"
3. .val() — from the resulting widget, retrieve the current value
The result is printed in your console and it represents the password:
Test
Actual URL
The actual URL includes many sub-domains. Something that's not easy to get unless you gain full access to the server that's handling the domain (i.e. the Domain Name Server or DNS in short.) So if you manage your own DNS, this is something you can easily inflict to other people if you have a lack of security on your system. At the same time, I think that many hackers purchase cheap domain names and use those to do such things. Some name registrar offer domain name specials like $0.99/domain. GoDaddy has done that a lot with the .info extension. Certainly because most people won't want to have a .info. it's considered useless and most often used by hackers or for sales purposes...
Anyway, the URL in that email was like this:
http://online.citi.com.us.jps.portal.index.do.promo.idspbl.cleaningrange.com.au/citi/index.htm
As we can see, the domain name itself is "cleaningrange.com.au", but the page starts with many sub-domains.
If you look closely, the domain names look very much like the correct Citibank URL:
http | online | .citi | .com | .us | .jps | .portal | .index.do | .promo | .idspbl | .cleaningrange | .com.au | /citi | /index.htm
https | online | .citi | .com | /US | /login.do | ?JFP_TOKEN=TGZUBM4U
They kind of go it wrong after the "us" part. They added "jps" and "portal" and then used "index.do" instead of "login.do".
Now, if you know anything about URLs, you know that the fake one are sub-domains and not the crrect URL. The "us" is lowercase and it starts with a period (.) instead of a slash (/). That's where things start breaking. The page, also, is index.htm instead of the expected login.do.
Of course, there is the fact that the URL starts with "http" instead of "https". This is a "lack of security" since this means the web page won't be sent to you encrypted. Newer browsers, though, will tell you not to fill out and send the form because it is not secure. Chrome actually just doesn't let you send the form at all in many cases, which I think is a good idea. All traffic over the Internet should have been encrypted since day one, but there weren't hackers at first and static pages can still safely be returned unencrypted. it's safe. The idea of having only encrypted accesses to all websites makes it safer because the only thing your ISP can know is the IP address of the server you are accessing. Beyond that, the data is encrypted so they do not get any information about it.
What composes a URL?
As I mentioned in my previous section, someone who knows about a URL will immediately see that the link in their email is wrong.
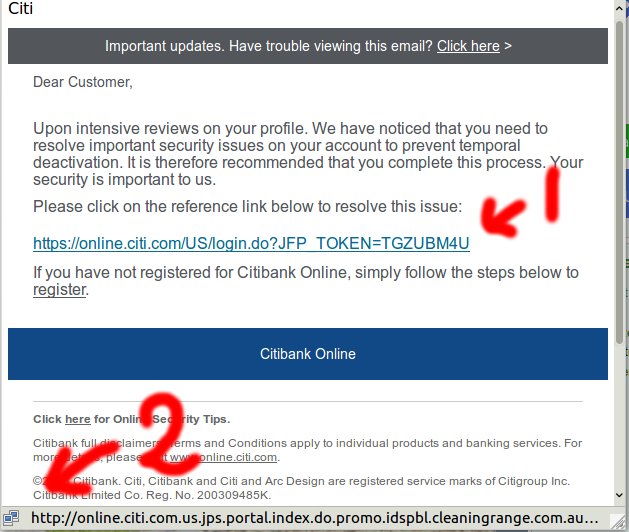
Here I show how I can see that the URL is a mismatch. First I see the URL in the email which definitely looks like it could very well be correct. Second, I see the real URL, the one where the browser would take me to if I were to click on that link. As we can see, that URL is the wrong one with "http" instead of "HTTPS" and ".us." instead of "/US/", etc.
So, this is not the URL to access Citibank.
Note that in many cases the other links will be correct and they will send you to the normal valid bank's pages. For example, you could have a link to the Terms & Conditions page. Clicking on that link may work 100% as expected. This is another way to better trick you in clicking the most important link and get you to sign up on the hackers website and steal your credential as that happens.
Now let's look at the various parts of a URL so you have a better chance, on your own, of determining whether a URL is genuine or not.
Protocol
The URL to a website starts with the protocol. We currently support two main protocols: HTTP and HTTPS.
If there is a mismatch, the visible link says "HTTPS" and the link the browser will use (the one in your status bar) says "HTTP", then there is a big problem already.
Domain Name
A URL includes some form of identification of the server that the browser needs in order to connect to the server. This is called the address which is composed of sub-domains and a Domain Name. The browser will query a Domain Name Server to convert that named identification to an IP address. In the old days, hackers would use straight IP addresses with numbers such as 192.168.0.1, but that generally fails now a day because servers have a default website and that number would reference that default which is not likely what would work for the hacker.
The Domain Name itself is the part between the sub-domains, such as "www" or "mail" and the first slash "/". Unfortunately, this is made rather complicated by the fact that various domain names have varying length Top-Level Domain. For example, the .com is simple. It's one section of the Domain Name. However, there are domains, such as ".cinema.museum" that have two, others have three: ".tas.gov.au" (Tasmania Government Australia), others have four: ".pvt.k12.ca.us" (Private School in California).
So, in a URL such as:
online.citibank.com
The Domain Name itself is just "citibank.com".
In the wrong URL from that email:
online.citi.com.us.jps.portal.index.do.promo.idspbl.cleaningrange.com.au
The domain name is "cleaningrange.com.au".
In many cases, country Top-Level Domain such as ".au" will offer a second level such as ".com.au" for Australian companies. However, this is not true in all countries. In France, for example, companies rarely use the ".com.fr", even though it is available.
On top of that, there are people who purchase regular domains and transform them in Top-Level Domains. For example, there blogspot Domain Name works as a Top-Level Domain with many country and other domain names. Since some countries do not offer a direct domain under their country Top-Level Domain, you also get some entries with three names such as ".blogspot.co.nz" for Newzealanders. There is a list of the blogspot.<...> as supported in early 2018:
.blogspot.ae .blogspot.al .blogspot.am .blogspot.ba .blogspot.be .blogspot.bg .blogspot.bj .blogspot.ca .blogspot.cf .blogspot.ch .blogspot.cl .blogspot.co.at .blogspot.co.id .blogspot.co.il .blogspot.co.ke .blogspot.co.nz .blogspot.co.uk .blogspot.co.za .blogspot.com .blogspot.com.ar .blogspot.com.au .blogspot.com.br .blogspot.com.by .blogspot.com.co .blogspot.com.cy .blogspot.com.ee .blogspot.com.eg .blogspot.com.es .blogspot.com.mt .blogspot.com.ng .blogspot.com.tr .blogspot.com.uy .blogspot.cv .blogspot.cz .blogspot.de .blogspot.dk .blogspot.fi .blogspot.fr .blogspot.gr .blogspot.hk .blogspot.hr .blogspot.hu .blogspot.ie .blogspot.in .blogspot.is .blogspot.it .blogspot.jp .blogspot.kr .blogspot.li .blogspot.lt .blogspot.lu .blogspot.md .blogspot.mk .blogspot.mr .blogspot.mx .blogspot.my .blogspot.nl .blogspot.no .blogspot.pe .blogspot.pt .blogspot.qa .blogspot.re .blogspot.ro .blogspot.rs .blogspot.ru .blogspot.se .blogspot.sg .blogspot.si .blogspot.sk .blogspot.sn .blogspot.td .blogspot.tw .blogspot.ug .blogspot.vn
This can be very confusing since ".blogspot.com" is considered a Top-Level Domain name as well. In other words, even the normally very simple ".com" Top-Level Domain name has now been spoiled in various ways. This is so complicated that we need very specialized code to check such Top-Level Domain names and I wrote a library just for that which I call libtld.
However, in most cases the banks will have their website using a regular ".com" so you should not worry too much about the other top-level extension. That being said, hackers are often using other country extensions, especially if it matches something in link with the URL that they want to offer in their emaill.
For example, the .do Top-Level Domain Name is from the Dominican Republic. One could use that ".do" with the name "login" or "index" so it looks like the path... (it's not unlikely that those two are currently protected or owned, though.)
FYI, the .do extension in the path means "Do Something". There is nothing to it specifically, other than it hides the language that the owner of the site uses. It could be PHP, Perl, C++, C#, Java, you just won't know unless it leaks that information in the HTTP or HTML headers, which for a bank is rather unlikely. That's a security issue to let people know what kind of technology you are using. So private businesses tend to hide that part of their websites to increase their security slightly.
Sub-Domain Names
Once you determined the domain name in a URL, then you can look for all the other names on the left side, separated by dots, and those represent the sub-domains. In our URL example, that's a great deal of data:
+------------------------------------------------------+---------------+-----------+ | Sub-Domains | Domain | Top-Level | +------------------------------------------------------+---------------+-----------+ | online.citi.com.us.jps.portal.index.do.promo.idspbl. | cleaningrange | .com.au | +------------------------------------------------------+---------------+-----------+
The sub-domain is used in the Domain Name Server and it can return a different IP address than the main Domain Name. This is very practical if you want to setup several servers, one per service that your company offers. For example, I could have a Domain Name definition file that shows the Name Servers, main Domain, WWW domain, and the Mail domain as follow:
mail A 10.0.1.1 ns1 A 10.0.2.1 ns2 A 10.0.3.1 www A 10.0.4.179
Here I show an example with private network IP addresses for sake of example. These numbers would not work correctly over the Internet.
The long sub-domain as shown in the email would actuall apear as follow in your DNS file:
online.citi.com.us.jps.portal.index.do.promo.idspbl A 10.0.4.183
As we can see, the IP address can be anything you want. So you can hack the Domain Name Server of a user on one server and put the IP address of another user's server where you hacked a Website or at least some Website space. This is another problem on the Internet as files shown in a webpage are not unlikely from many different locations. This is especially true now that many companies are usingthe cloud instead of one server do it all method which breaks as soon as too many people attempt to view your content.
Path
As I mentioned above, the sub-domains and domain name start and end with a slash.
Starting at the slash after the domain name, we have what's called a full path. All resources on a webserver are always referenced with a full path (as long as your browser is concerned.) Within a page, you can reference other pages with a relative path. However, when you click on such a link, the browser transforms the relative path in a full path first, then sends that full path to the server.
The path ends either with a question mark (?) or a hash character (#). The data after a question mark is called Query Strings. The data after the hash character is called the Anchor. Query strings are used to define parameters on how to retrieve the data. For example, if you are to download a file, there could be a query string defining the format: format=PDF or format=DOC. The Anchor, on the other hand, is used to reference data within the page. For example, if I were to put a Table of Content at the top of this page and anchor names on each section such as this Path section, it would allow you to click on a link with "#path" and that would take you to the Path section. The browser would scroll the content of your window so you would see the Path section. Note that the anchor syntax has been used for other things, but that's not legal anymore. Also, the anchor is not sent to the backend server. It's private to the browser.
The path defines the file that is going to be loaded from the server. The file can be a script that will be run by the webserver to generate the HTML or other content. How that part works is not too relevent to you, although it can be useful to know that if there is a .php or some other well known extension, the server will dynamically create a form and that can give it a chance to tailor the form to you. For example, they could show you your name or your email address when you return to their website. This is pretty powerful when you are not too sure whether the email was a scam or not to start with.
Now, we have noticed that in our case, the email displayed URL says:
/US/login.do
When the real URL says:
/citi/index.htm
Quite a discrepancy and really easy to detect.
Further, there is a Query String in the displayed URL:
?JFP_TOKEN=TGZUBM4U
and the real URL does not have any Query String. Yet another hint that this is fake.
I know and understand that this is quite technical, but knowing such things allow you to immediately know that an email is total junk and just "Junk" it immediately.
Reporting Such Emails
For financially related scam emails, it's a good idea to send it to the corresponding bank so they can ask the concerned ISPs/website owners to turn off the hacker's webpage. If that is done quickly, it allows the bank to prevent further potentially hacked users. Actually, I very often see a 404 Page Not Found error when I try to follow such links. This means someone in the middle prevented the link from working as expected.
The FTC also has an email you can use to report such scams: spam@uce.gov
There is a link to the page about Citibank Scam Emails.
You can find the one from your bank by either going to their home page and searching for a link from there or using a search engine such as Google and searching for "bank name abuse" or "bank name scam email" (do your searches without the quotes). In most cases that will give you the correct result.
Note that a good idea is to forward the email to them after you turned on "All Headers". Otherwise they won't be able to do as much as they could. The "All Headers" feature means that the source of the email will be included in your report. That can be used to ask the source to prevent further sending of that email.
Although there are many ways at the disposal of banks and other financial insitutions to block hackers, they need them to be reported. What I think is sad is that in many cases, most of this hacking could be avoided if only emails were not still using 1982's technology without security improvements...
